The High Compression Deception: A Reality Check on Historians vs Open-Source Databases

Open-source databases have recently been stealing the spotlight in numerous industries, including process sectors such as oil and gas, chemicals, pharmaceuticals, and utilities. Historically, Historians were the preferred choice due to their user-friendly domain-specific tools, seamless interaction with industrial equipment, and most notably, their high compression rates. However, the notion of compression in the context of Historians differs significantly from the conventional IT understanding, and that's where the heart of the matter lies.
Earlier, we published an article titled "Historians vs Open-Source Databases - Which is Better?" where we drew parallels between InfluxDB, TimescaleDB, and Historians, analyzing the hurdles they face. We identified compatibility issues in modern landscapes for Historians and a lack of usability for Operational Technology (OT) personnel in open-source databases. We proposed the United Manufacturing Hub as a potential bridge to these gaps, enhancing the user-friendliness of databases like TimescaleDB for OT engineers. However, we did not explore the arena of compression and retention then, which sparked curiosity amongst our readers about the comparison between open-source databases and Historians like Canary and AVEVA PI (formerly OSIsoft PI).
The business case for compression is very weak nowadays
Let's take a moment to ask why we compress data. The straightforward answer is to cut storage costs. But in a time when storage costs are dropping, should compression still be a priority?
Consider an OPC-UA server with 30k data points for an energy reactor, and assume we fetch all data points every second. This would generate around 3.7 TB of data annually, amounting to 37TB in 10 years. Storing this data uncompressed in a cloud-based S3 bucket would cost a mere $851/month (0.023 USD per GB, us-east (Ohio) in AWS). Apply a standard IT lossless compression algorithm, and that cost plummets to about $50/month. And if you're willing to wait a few seconds for your data, the cost drops even further.
By comparison, the proposal for OSIsoft PI by the city of Holland revealed a $100k one-time fee for 10k tags plus a $15k annual maintenance fee. If we scale this down from our 30k tags to 10k tags, the software maintenance of OSIsoft PI is roughly 100x more expensive than S3 storage, even without considering one-time costs, personnel, training, and other costs.
[...] the software maintenance of OSIsoft PI is roughly 100x more expensive than S3 storage, even without considering one-time costs, personnel, training, and other costs.
This comparison is of course not entirely fair, as historians provide much more than simple storage. However, it shows you that you should not buy an historian only because you want to store data for regulatory purposes - you can do that much cheaper.
Other reasons to use an Historian
Historians are not merely data storage vessels; they deliver much more. Their capabilities range from data collection, contextualization to visualization. However, it is crucial to remember that even though these features are customized for manufacturing and bundled as a single package, they often fall short when compared to professional tools dedicated to a single function.
For instance, when it comes to visualization, specialized software like Grafana or Microsoft PowerBI tends to offer more robust capabilities than PI vision or PI DataLink, but might not be perfectly usable for an OT engineer. We wrote about this in our previous articles about "Open-Source Databases vs Historians".
The cost aspect of data storage has already been dissected. It's been established that Historians, on a comparative scale, can be up to 100 times more costly.
Another aspect to consider is the integration of Historians with contemporary Docker or Cloud-based IT landscapes, frequently monitored with tools like Prometheus. Many Historians operate exclusively on Windows, presenting hurdles for seamless integration with the broader IT infrastructure. We also write about this in a previous article (see above).
Addressing compliance concerns, rest assured that major cloud platforms such as AWS, Azure, or Google are all GxP compliant, meaning they adhere to regulatory quality guidelines and practices.
Given the aforementioned points, it seems that the only justifiable reason left for using a Historian is if you want to gather, contextualize, and store data, without doing anything more and don't want to worry about maintenance or setting up their own systems. Just buy something, and be done with it. This additionally, comes with a monetary cost.
However, if your intent extends beyond mere data storage, say, to areas like IT / OT convergence, Unified Namespace, sending data to the cloud, or real-time AI analysis, you'll find yourself limited by the technical restrictions of traditional Data Historians.
So, how can one replicate the functionalities of a Historian without such limitations? Stay tuned for our next chapter, where we will explore promising alternatives to traditional data Historians, focusing on their practical applications and benefits.
Open, modular, and event-driven architecture
Beginning a transformative journey doesn't require abruptly discarding old Historians. Creating discontent among stakeholders is not a desirable starting point. However, building upon the technology of the 90s comes with its fair share of technical constraints. A gradual shift towards a new foundational architecture seems like a viable solution.
In our perspective, an open, modular, and event-driven architecture – a "Unified Namespace" – provides the most effective approach. Rather than directing all data straight to the Historian, consider rerouting it via an MQTT/Kafka broker. A commonly used topic structure adhering to the ISA95 standard, such as enterprise/site/area/productionLine/workCell/tagGroup/tag, has been reported by several companies we've interacted with. Continuous data points are sent for time-series "tags", while changes such as "addOrder", "changeOrder", or "deleteOrder" are sent as events for batch data, master data, or relational data. This could be fetched from existing databases using a Change Data Capture (CDC) tool like Debezium, or ideally directly from the PLCs or MES as events.
This architecture provides an immediate benefit: it propels you into the contemporary IT landscape of 2023, liberating you from the confines of 90s technology. You can now transmit a higher number of tags/data points leveraging current IT technology, which has a vast capacity (think Google, Facebook, and TikTok). From this point, you can route the data back to Historians, although down sampling may be necessary given their typical data handling capacity. Within the MQTT/Kafka broker, you could implement "Exception Reporting / Dead-band" to minimize data, if required. In most cases, this will be unnecessary.
Next, to foster a stronger connection with IT, you need two types of databases: one for real-time data access, also known as Online Transactional Processing (OLTP), and another for data analytics, referred to as Online Analytical Processing (OLAP).
A relational database like PostgreSQL is suitable for real-time data access. For time-series data, you need a time-series database such as TimescaleDB or InfluxDB. As we have elaborated in previous articles, our preference is TimescaleDB due to its efficiency in storing time-series data, in addition to being a functional PostgreSQL. Regular exports of data (for instance, daily) can be directed to an OLAP database, such as a data lake. TimescaleDB, when used in the cloud, allows for automated outsourcing older data points to S3, thus benefiting from cost savings at the cost of increased query times., which could be acceptable for very rare queries.
Finally, a visualization tool like PowerBI or Grafana can be layered over the OLTP "SQL" database. Add a team of data scientists to manage your data lake, and you're set.
In assessing the options for data storage, cost consideration is crucial. We can evaluate this from two major perspectives: using a managed Timescale Cloud instance or self-hosting TimescaleDB on an on-premise server. The same goes for any other Timeseries Databases such as InfluxDB (see also side-note).
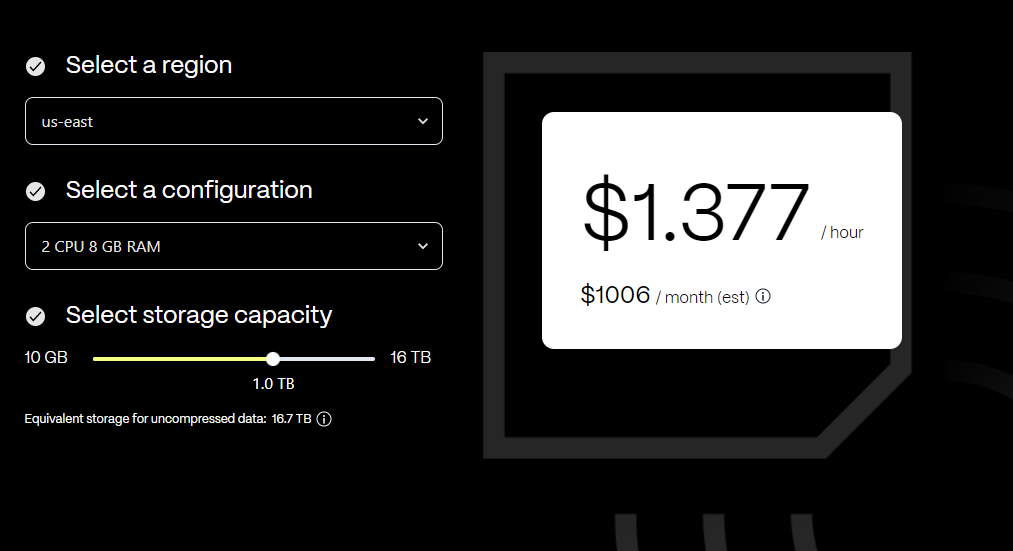
- With a cost of approximately $1,000 per month, you can store up to 10,000 tags per second over a ten-year period (~12TB in total) using TimescaleDB Cloud (nowadays just called Timescale, see screenshot further below). This package is all-inclusive, meaning that it doesn't necessitate any additional expenditure for maintenance, further storage, or compute costs.
Moreover, cost optimization techniques can further reduce this monthly expense. For instance, implementing exception reporting is one such strategy that has proven beneficial in bringing down costs.
In addition, consider the option of archiving data that is older than a year and is not accessed daily. By moving such data to S3 storage, you can continue to access it for regulatory purposes without incurring the daily storage cost on your primary platform. - An alternative to the managed cloud instance is setting up your own TimescaleDB on an on-premise server. The primary cost factors here are the server costs and the personnel expenses to maintain the server.
This option offers a high degree of control over your data and infrastructure. However, it also comes with the responsibility of dealing with maintenance issues, such as handling disk failures.
For a quick setup of this infrastructure, consider exploring the Open-Source United Manufacturing Hub and our commercial Management Console. These tools can significantly assist in maintaining such an infrastructure across multiple plants.

Summary
This article challenges the traditional use of Historians in sectors like oil and gas, chemicals, pharmaceuticals, and utilities, as open-source databases have emerged as potential alternatives. We delve into the limitations of Historians, particularly their compatibility issues with modern landscapes, and shed light on the advantages of open-source databases, proposing the United Manufacturing Hub as a bridge to these gaps.
In the context of data compression, which Historians are often praised for, the necessity for this feature is questioned in the current era of declining storage costs. A comparison is made between cloud storage costs and Historian maintenance costs, revealing that the latter can be up to 100 times more expensive.

Despite the benefits Historians offer, such as data collection, contextualization, and visualization, they often fall short when compared to dedicated single-function tools. We argue that Historians' integration with current Docker or Cloud-based IT landscapes can be cumbersome and that dedicated software often provides more robust capabilities.
The need for a transition from the outdated technology of the 90s to a more modern IT landscape is emphasized. We advocate for an open, modular, and event-driven architecture, using an MQTT/Kafka broker for data routing. This approach positions you at the forefront of the contemporary IT world, allowing for more significant data transmission and connectivity.
The use of databases for real-time data access and data analytics, along with visualization tools and a team of data scientists, is advised to manage this new landscape. The United Manufacturing Hub and our commercial Management Console are proposed as efficient tools to set up and maintain this architecture across multiple plants.
Thank you Rick Bullotta, James Sewell (TimescaleDB), Michael Bartlett (quartic.ai), Bharath Sridhar (Deloitte), Alyssa Nickles (InfluxDB) for your valuable feedback in creating this article!
We've contacted the company AVEVA for a comment (like we did with TimescaleDB, InfluxDB, and Canary), but did not receive any answer. Canary replied initially very quickly, but has not provided the feedback yet.


